
微軟(Microsoft)上周公布新人工智能(AI)模型VASA-1,只要上載肖像硬照及錄音,AI就可合成影片,讓相中人「說話」。並以名畫蒙娜麗莎作示範,讓畫中蒙娜麗莎說唱起來,效果相當驚艷搞笑。但搞笑聲過後,坊間普遍憂慮會被濫用冒充真人,加劇網絡騙案,假資訊氾濫。微軟亦坦承的確有濫用疑慮,故VASA-1目前不打算將新模型開放公眾使用。

微軟表示,開發此項最新的虛擬人像技術VASA-1原意希望用於教育、協助有溝通障礙的人,創造出虛擬的 AI 角色讓他們練習交談,甚至為人類創造虛擬伙伴。VASA-1只要使用一張照片以及一段語音音訊,就能夠產生精確的人臉對嘴說話影像,甚至可展現自然的表情和頭部動作。
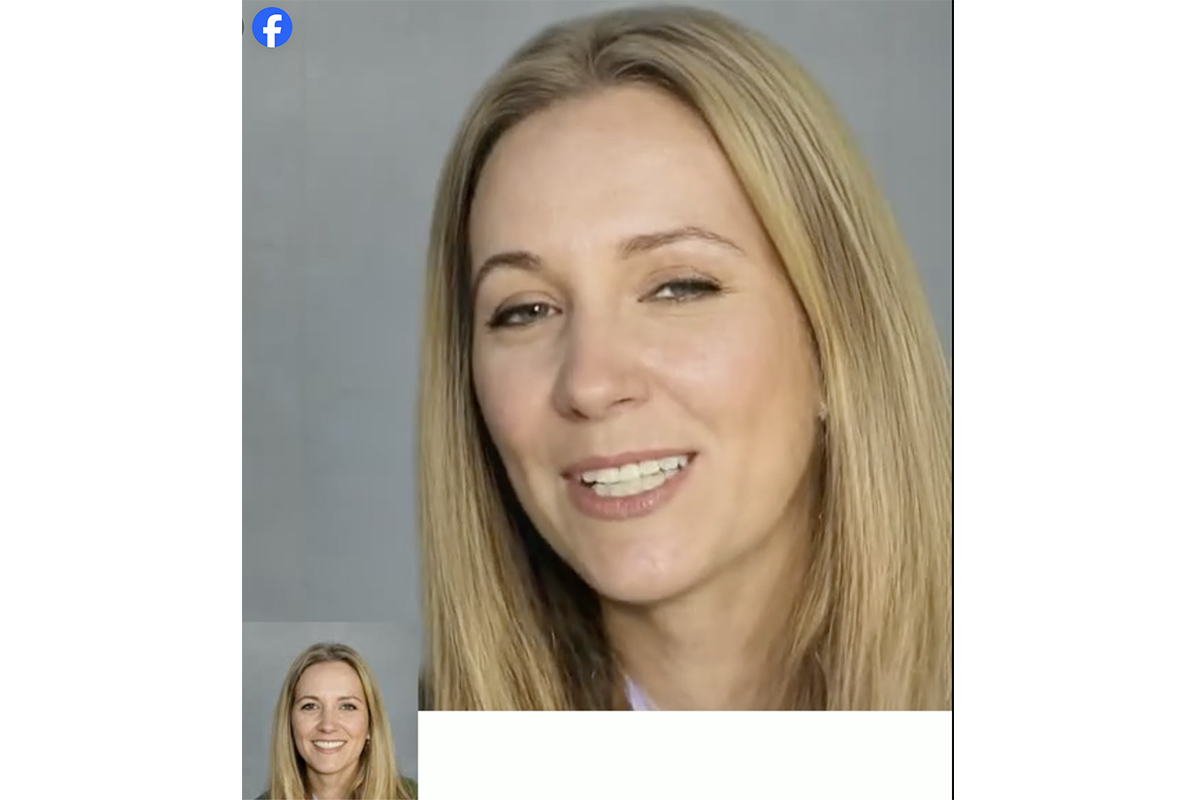
微軟指,VASA-1是以 VoxCeleb2 資料集為基礎進行訓練,有關資料集收集了YouTube 影片中超過6,112位名人的100萬個語音片段,以大量人類說話的面部動作影片訓練新AI模型,包括人類表情、嘴唇動作、眼神及眨眼等,令生成影片更逼真。微軟指VASA-1現時能即時生成每秒最多40幀的512×512影像,適合虛擬形象的即時互動用例。除了真人照片,畫作如蒙娜麗莎或動畫人物,跟要配上文字或音檔便可合成影片。不過研究團隊強調,該技術主要用於研究,而非實際產品或 API 發布。
蒙娜麗莎說唱以及一系列VASA-1生成的影片發布後,引來不少掌聲,指「看不出來,厲害!」但其逼真度亦同時引起不少網民憂慮,認為VASA-1會加劇網絡騙案:「這個要道德監管了吧隨便一張照片就可以弄出沒講過的話」、「完全沒有抵抗力,真的會相信」、「如果沒有事先講AI生成,應該看不出來」,「我有一個大膽的想法⋯⋯」,更有網民直言,「有片有真相」這句話將不再言之有理了。@
-------------------
局勢持續演變
與您見證世界格局重塑
-------------------
🔔下載大紀元App 接收即時新聞通知:
🍎iOS:https://bit.ly/epochhkios
🤖Android:https://bit.ly/epochhkand
📰周末版實體報銷售點👇🏻
http://epochtimeshk.org/stores



















